
I thought all my walkthroughs on the Timeless Isle were complete. I kicked back with a well-earned chocolate chip cookie and waited for the patch. I was excited to get my mini Xuen, run around in the Shrine of Seven Stars for a while showing it off, and make a small fortune on new glyphs. Then, I see this jerk.

Look at that smug little face. I’m guessing that the trigger to seeing his daily is something along the lines of defeating Aki, but I’m really not sure. I’d heard occasional discussion about him during PTR, but never saw that he had anything for me, so I kind of ignored him. I’m kicking myself over this now, trust.
Tommy Newcomer only has one pet. So we should totally take pity on him, right?
WRONG.

Lil Oondasta is the pet equivalent of, well, boss Oondasta. With a very strong AOE and a force swap, she is a brutal fight. Luckily, she’s only one mob, and you can heal and re-try as many times as you need to get her down. For 500 Timeless Coins and 20g. Ugh.
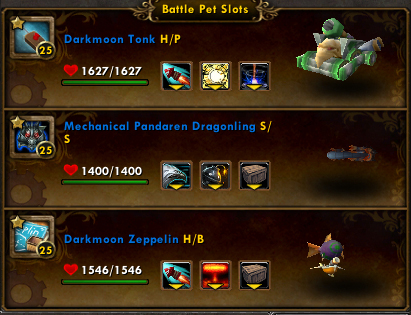
Here’s the team I ended up using:
Oondasta has 3 abilities, and her 2 most deadly are Magic: Frill Blast (force swap) and Spiritfire Beam (the AoE). She backs that up with Crush, which is a big hit in itself. Because of the humanoid nature of Crush, trying to use my Golden Hatchling in concert with the Clockwork Gnome was met with a hearty ‘lol u mad’ from Oondasta.
The reason I like the Zeppelin and the Mechanical Dragonling should be fairly obvious. Decoy is an amazing ability this fight, and I want to abuse it as much as possible. I definitely screwed up a bit on the Dragonling’s moveset though… Frill Blast will always swap in the Zeppelin for me, because of the higher health, so unless I manually swap for a Fly By, I’m not going to use it to buff others, and the Dragonling doesn’t really have other moves to buff itself. Though there’s not a ton of damage we have to do, the breath ability will probably make for a cleaner fight.

The reason I go with the Tonk is that, because of the force swap if I use Ion Cannon off the bat, Oondasta will then immediately swap him to the back row for the recharge turn and the vast majority of the cooldown I have before I can cast it again. If I return to the front row on my pre-res turn, I can also get in a Shock and Awe for a hopeful-maybe stun. Oondasta is slower than all my pets and only has single hits, so once she kills my mechanicals the first time, they’re guaranteed at least one extra hit. As long as they don’t die in the back row, anyway.
I really liked using two Decoys. I don’t think that both are entirely necessary, especially given the relatively paltry firepower on the Dragonling. Explode as a mechanic is a really excellent tool for single fights, so I would definitely recommend using at least one of these pets.
The Tonk is a little more debatable. You can definitely try subbing in either the Menagerie Custodian or the Tranquil Mechanical Yeti, both of which use Ion Cannon. They’re a bit less sturdy, but it’s still an option. If you go with the Yeti, you may want to opt for Thunderstorm instead, and pair it with a Clockwork Gnome’s turret. In general, as long as you have a good amount of mechanical offense and aren’t caught off-guard by the force swap, you’re going to be in good shape.
A final note: I don’t like writing strategies with pets which are prohibitively expensive or difficult to get without at least offering a solid alternative (eg, Emerald Proto-Drake can be substituted for the Emerald Whelpling in most settings). With that in mind, the Son of Animus, specifically Interrupting Jolt, really shines this fight in place of the Tonk. I want to stress that this investment isn’t necessary, but I can generally keep that last pet alive entirely (well, minus an AoE or two) if I use Animus here.








